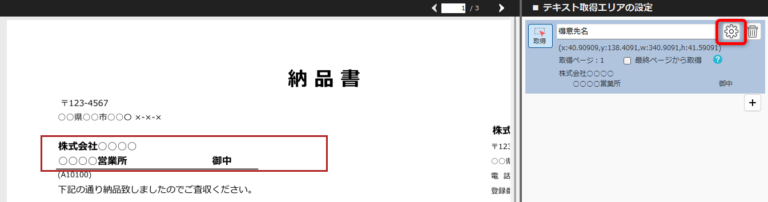
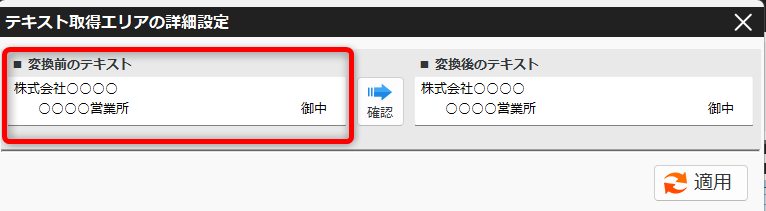
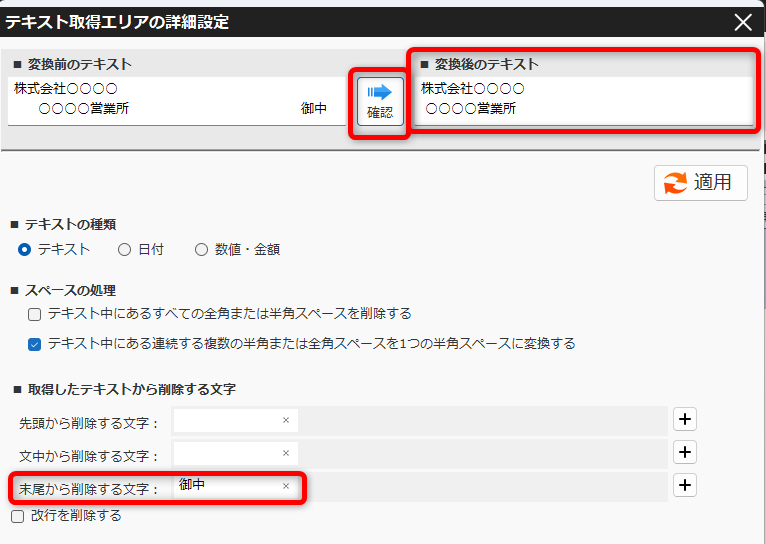
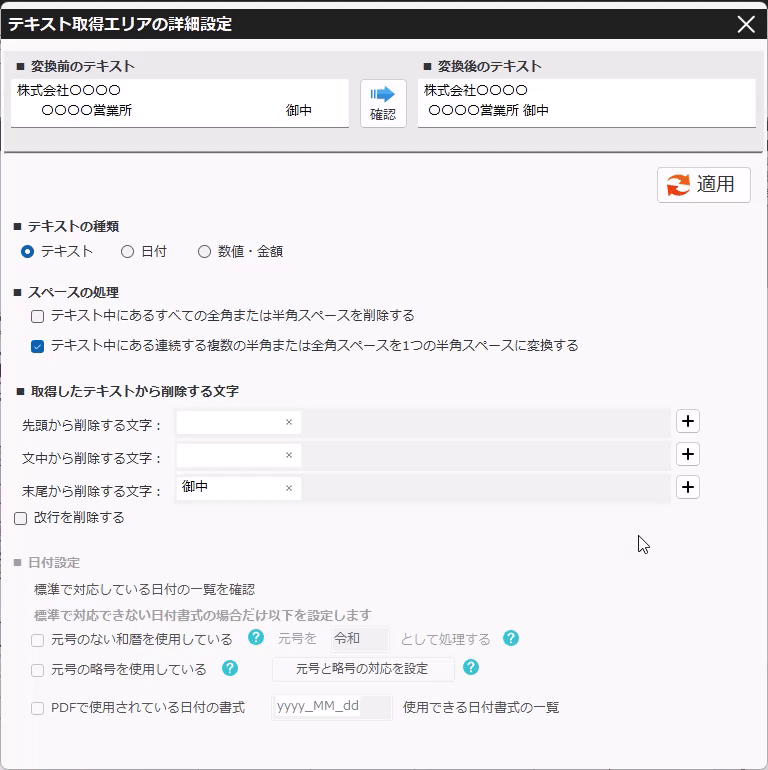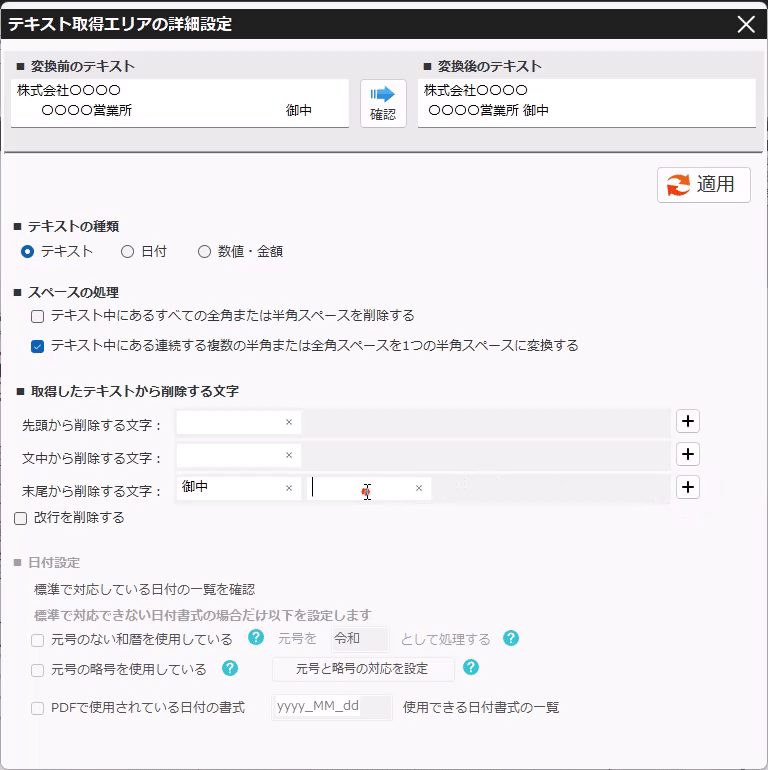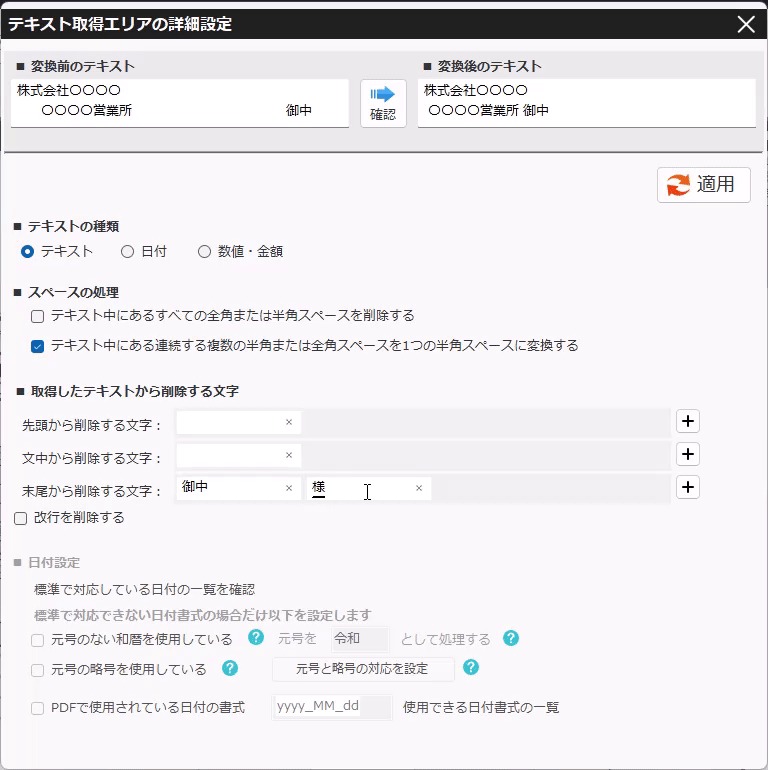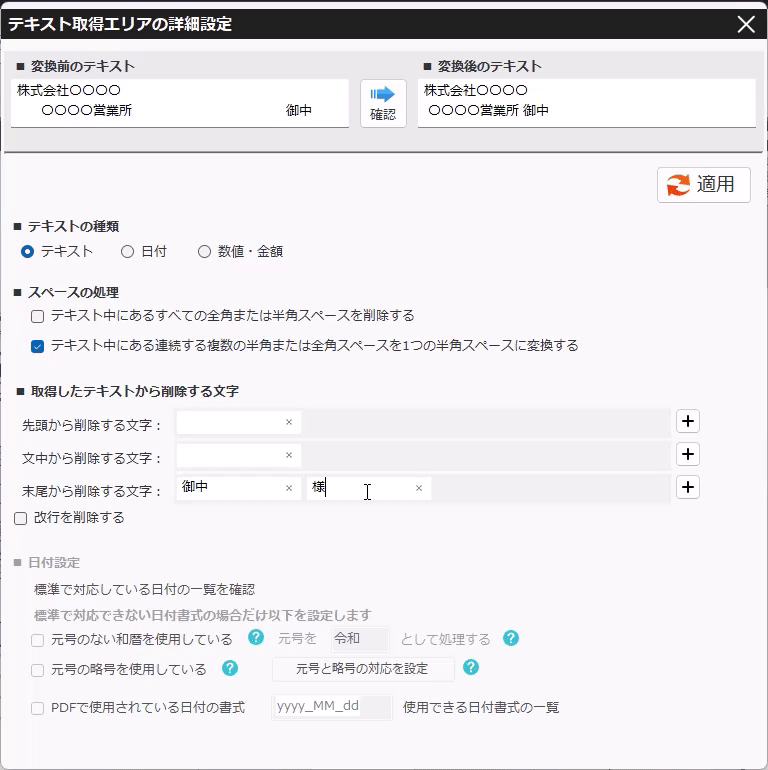
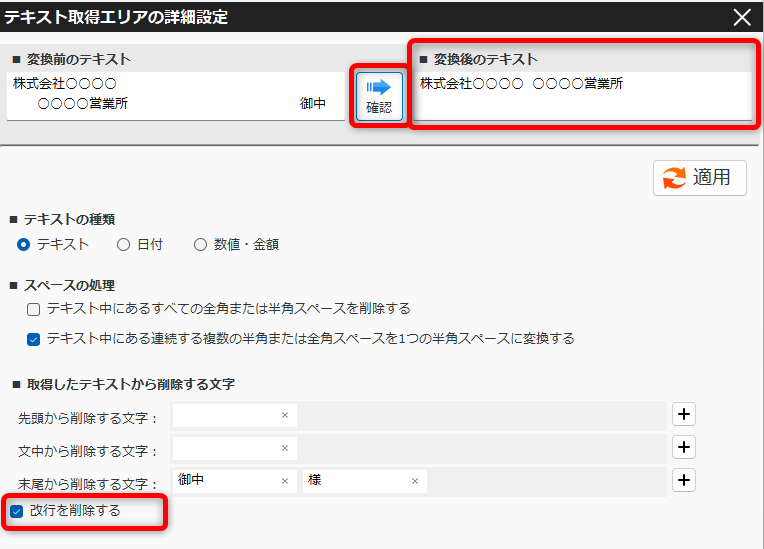
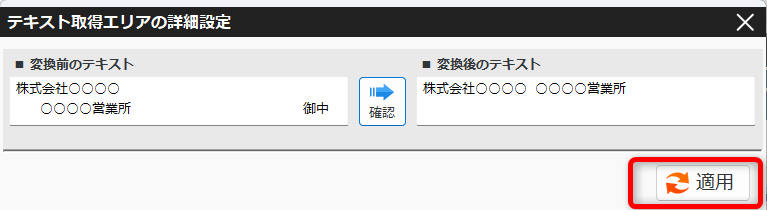
PDFから抽出したテキストの加工(不要文字・改行の削除) 投稿者:clippdf 投稿公開日:2025年3月9日 投稿カテゴリー:ガイド 取得したテキストから不要なテキストを処理する手順を説明します。 使用するオプション機能 PDF上のテキストを自動で一括取得 PDFからテキストを取得するページ まず、取得したいテキストをPDF上でドラッグします。 歯車ボタンをクリックし詳細設定画面を開きます。 詳細設定画面の左上に表示されているて「変換前のテキスト」がPDF上から取得したテキストです。 テキスト中の不要なテキストを削除する 得意先名の最後にある敬称「御中」を削除します。 「末尾から削除する文字」に「御中」と入力し、確認ボタンをクリックします。変換後のテキストの末尾から「御中」が削除されていることが確認できます。 敬称の「御中」だけでなく、「様」も削除する場合は、「+(プラス)」ボタンで入力欄を追加し、削除対象の文字を設定します。 テキスト中の改行を削除する 得意先名内の改行を削除するには,「改行を削除する」チェックボックスを選択します。 確認ボタンをクリックすると、変換後のテキストから改行が削除されていることが確認できます。 設定を保存する 設定後は「適用」ボタンをクリックして、設定内容を保存します。 タグ: PDF上のテキストを一括取得 その他の記事を読む 前の投稿数値や金額を取得する 次の投稿日付を取得する(和暦の変換) おすすめ 保存済みの設定を削除するには 2025年3月4日 PDFからテキストを抽出する方法(基本) 2025年3月8日 保存済みの設定を編集するには 2025年3月4日