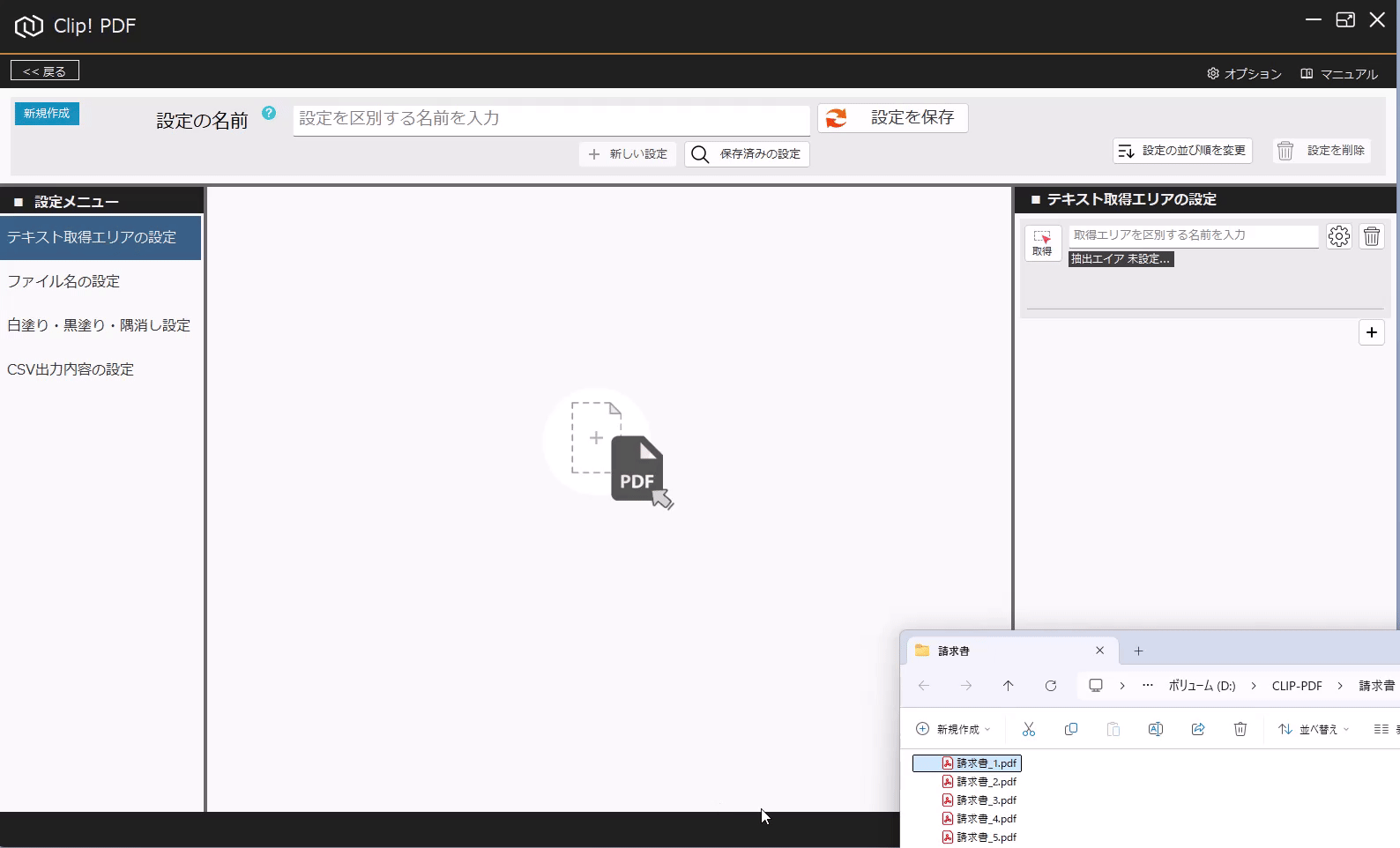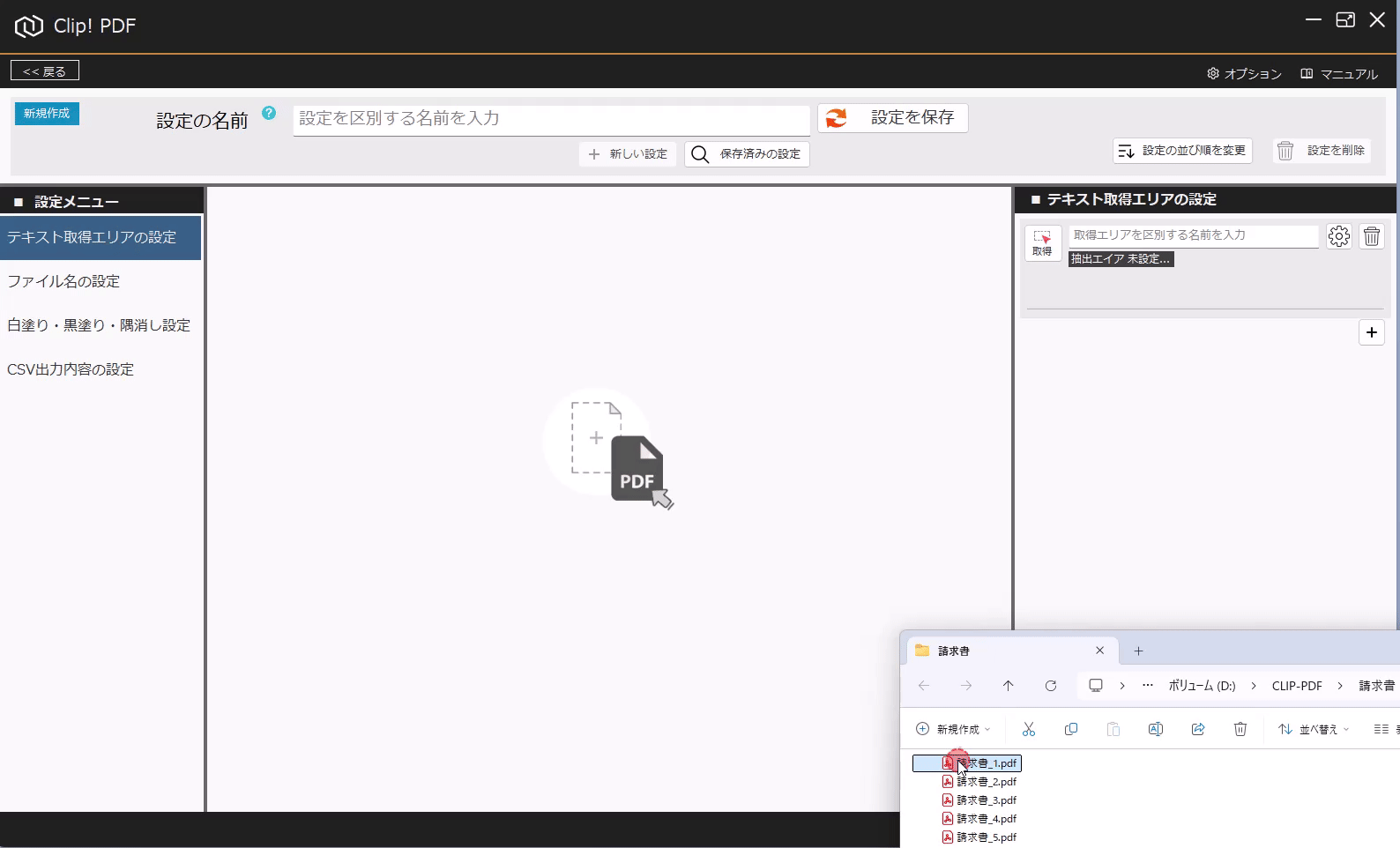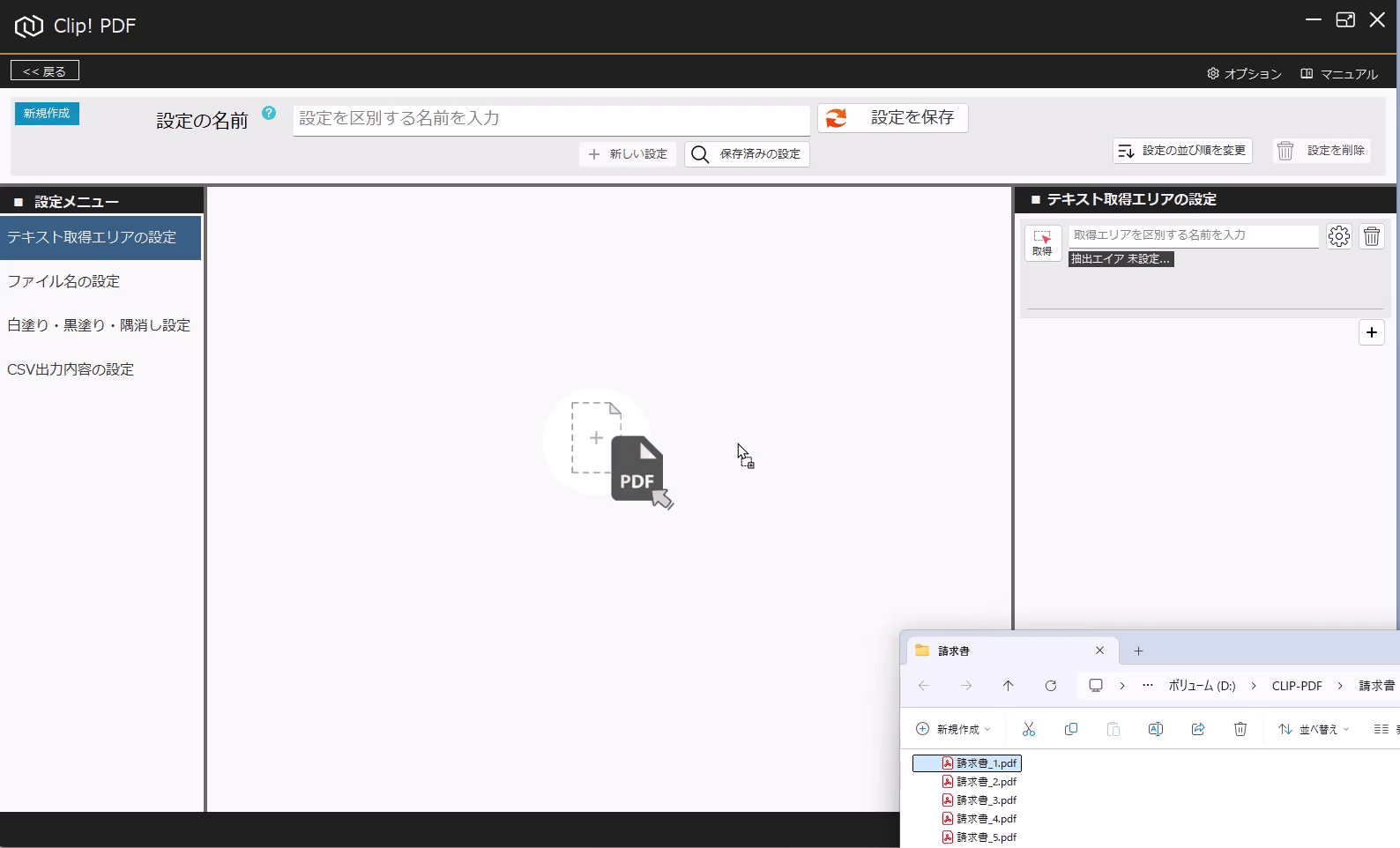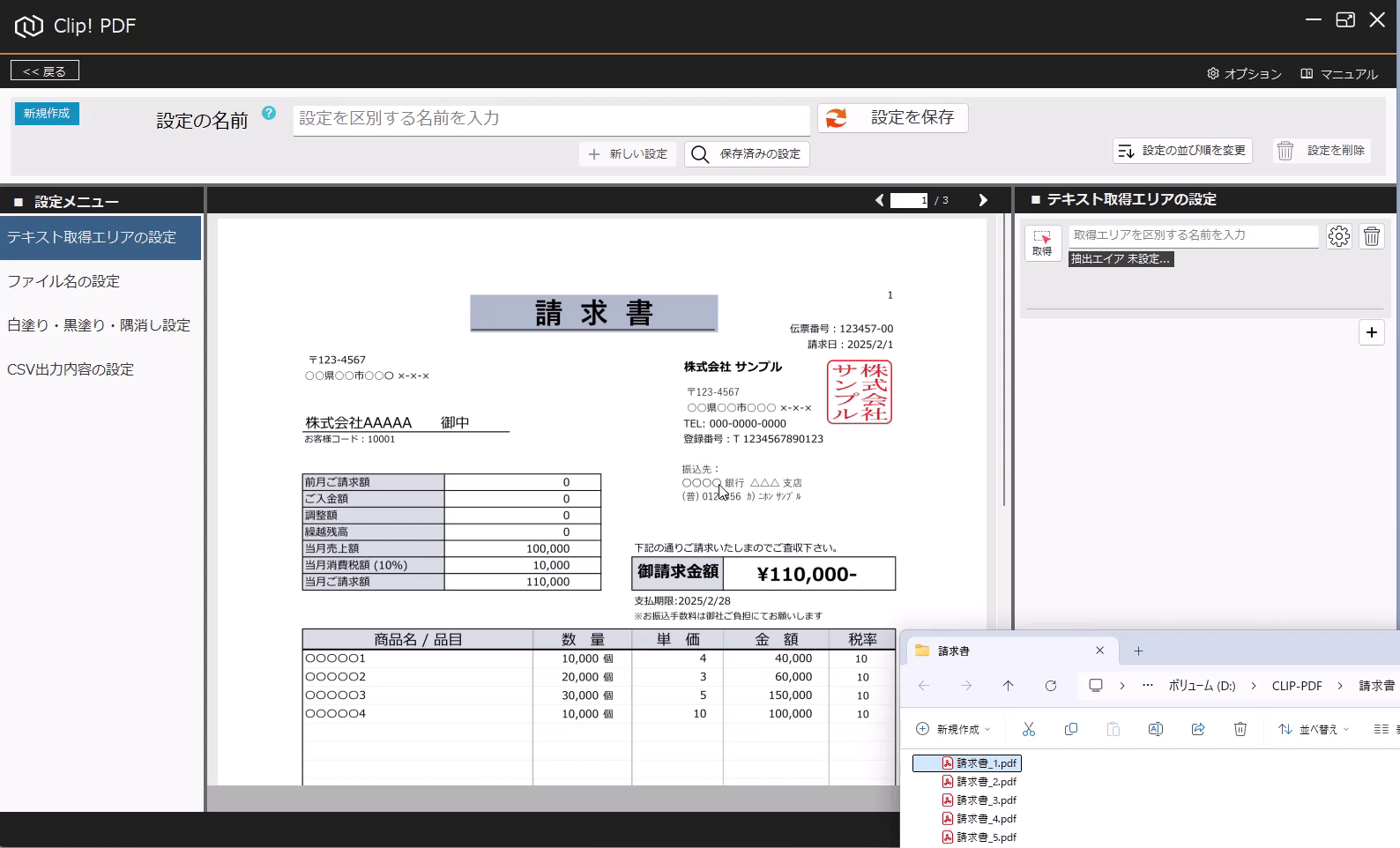
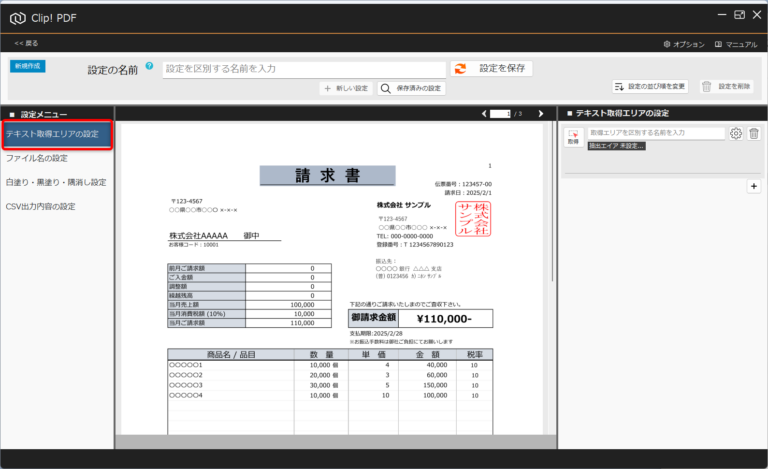
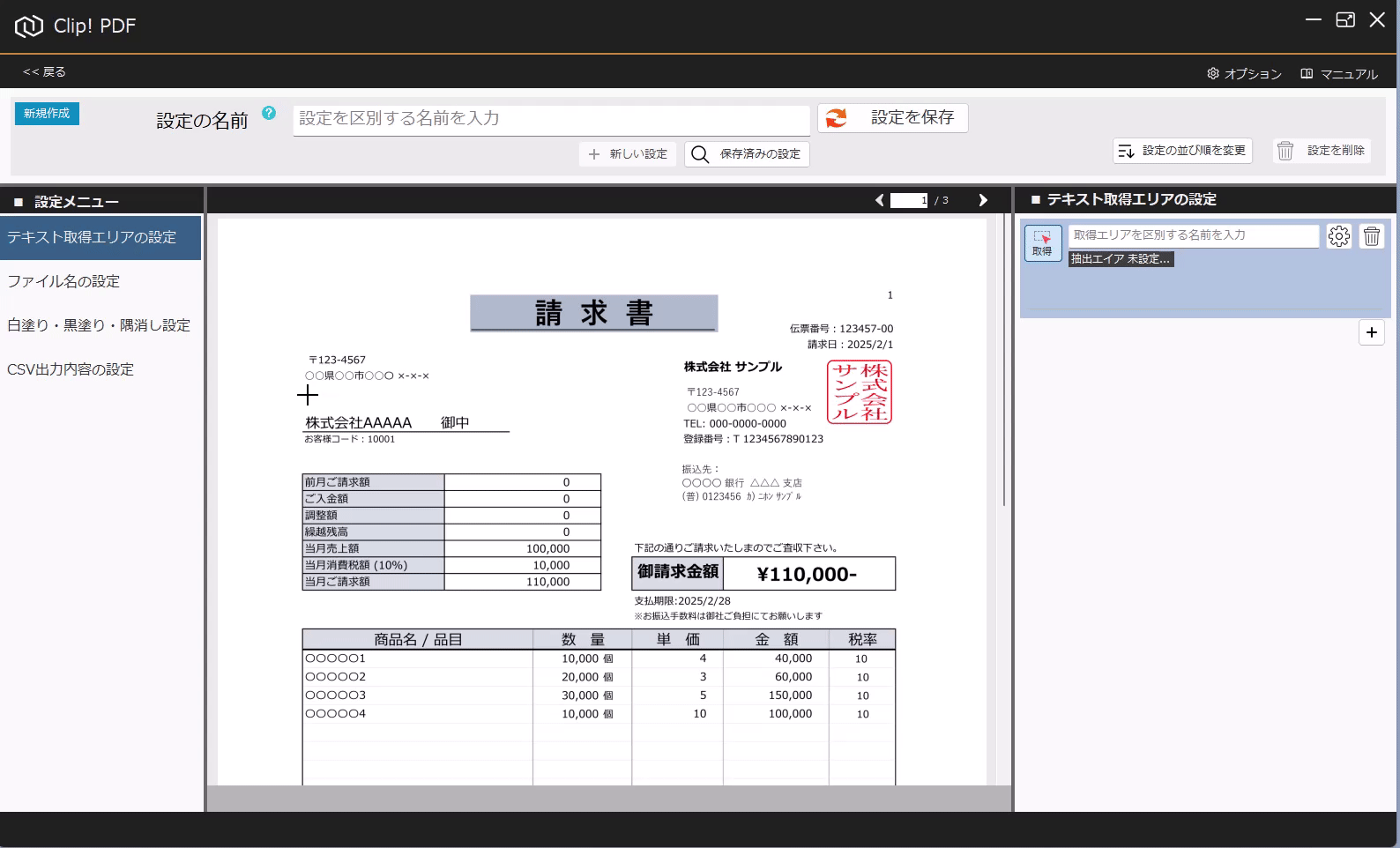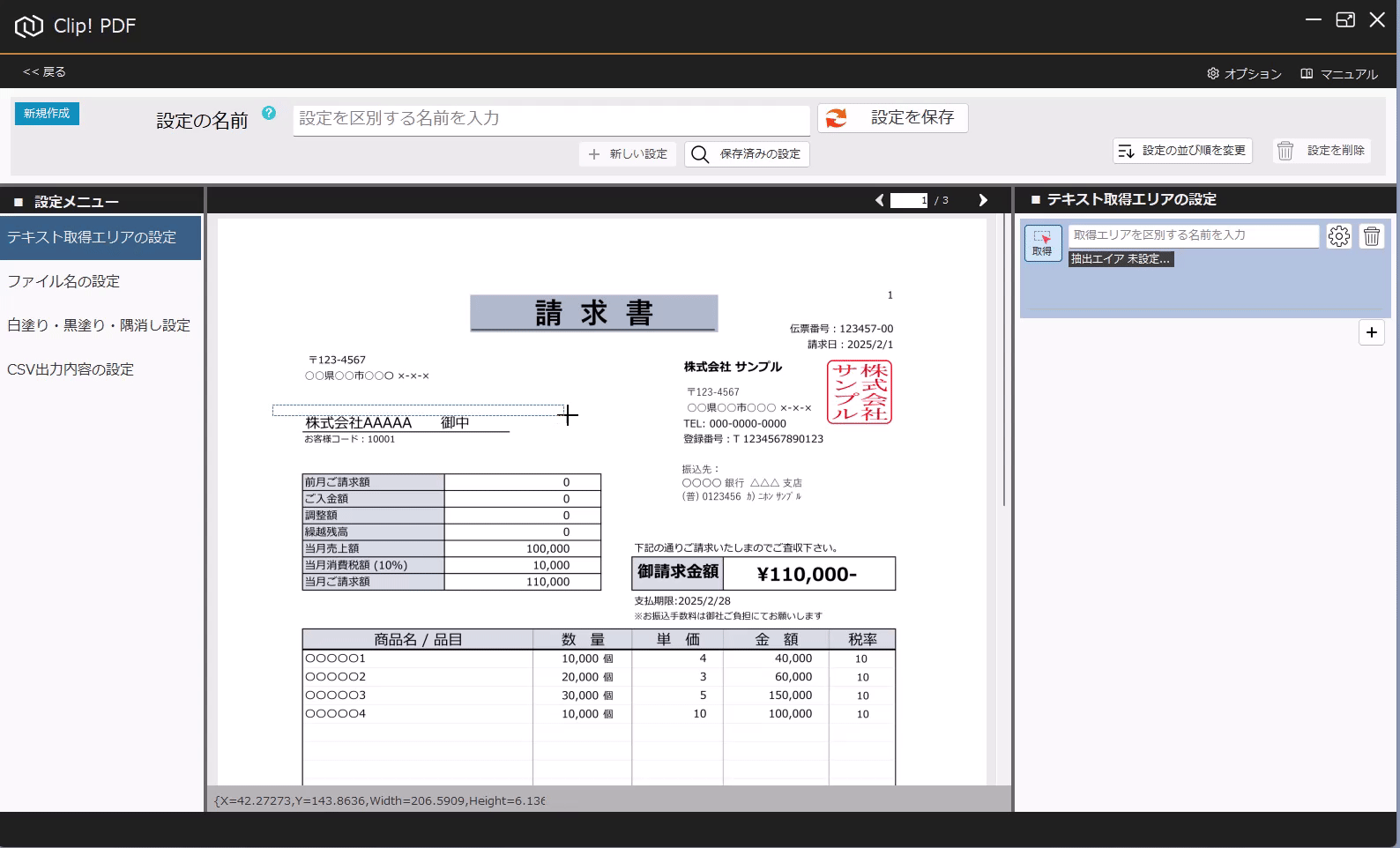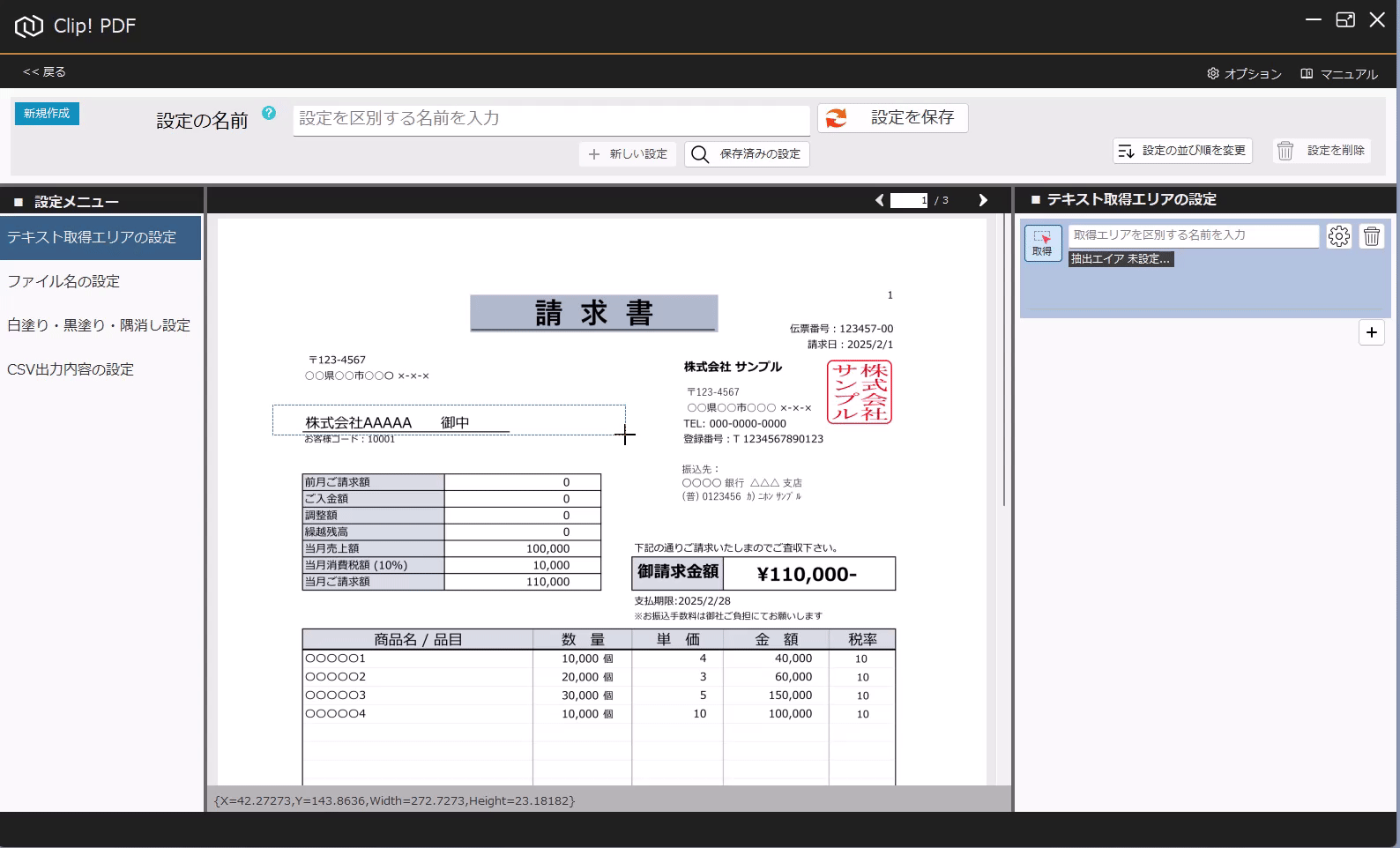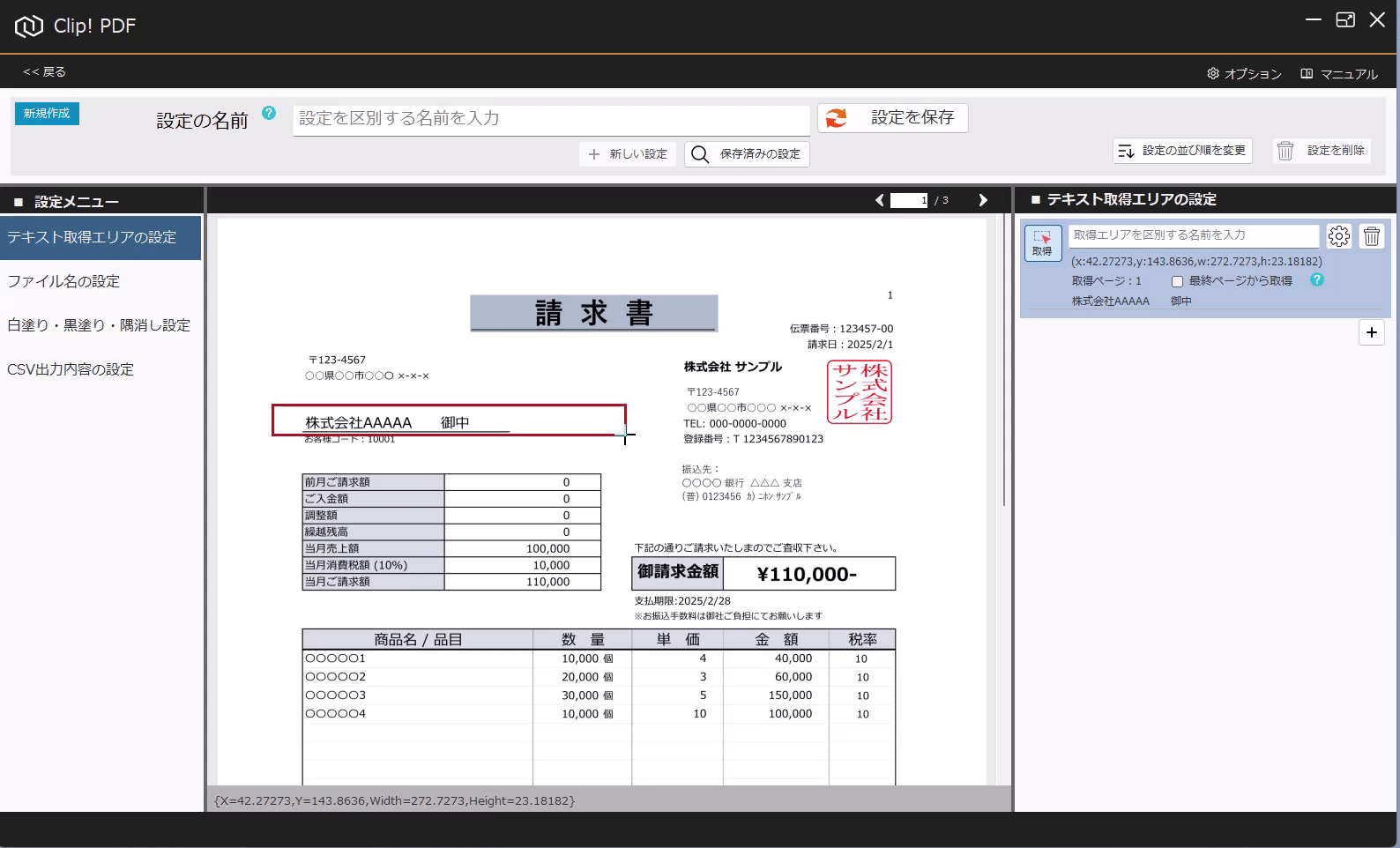
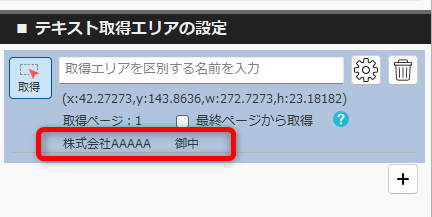
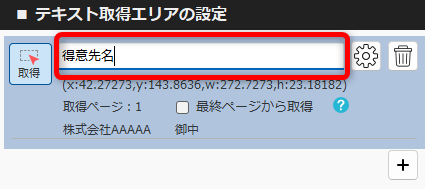
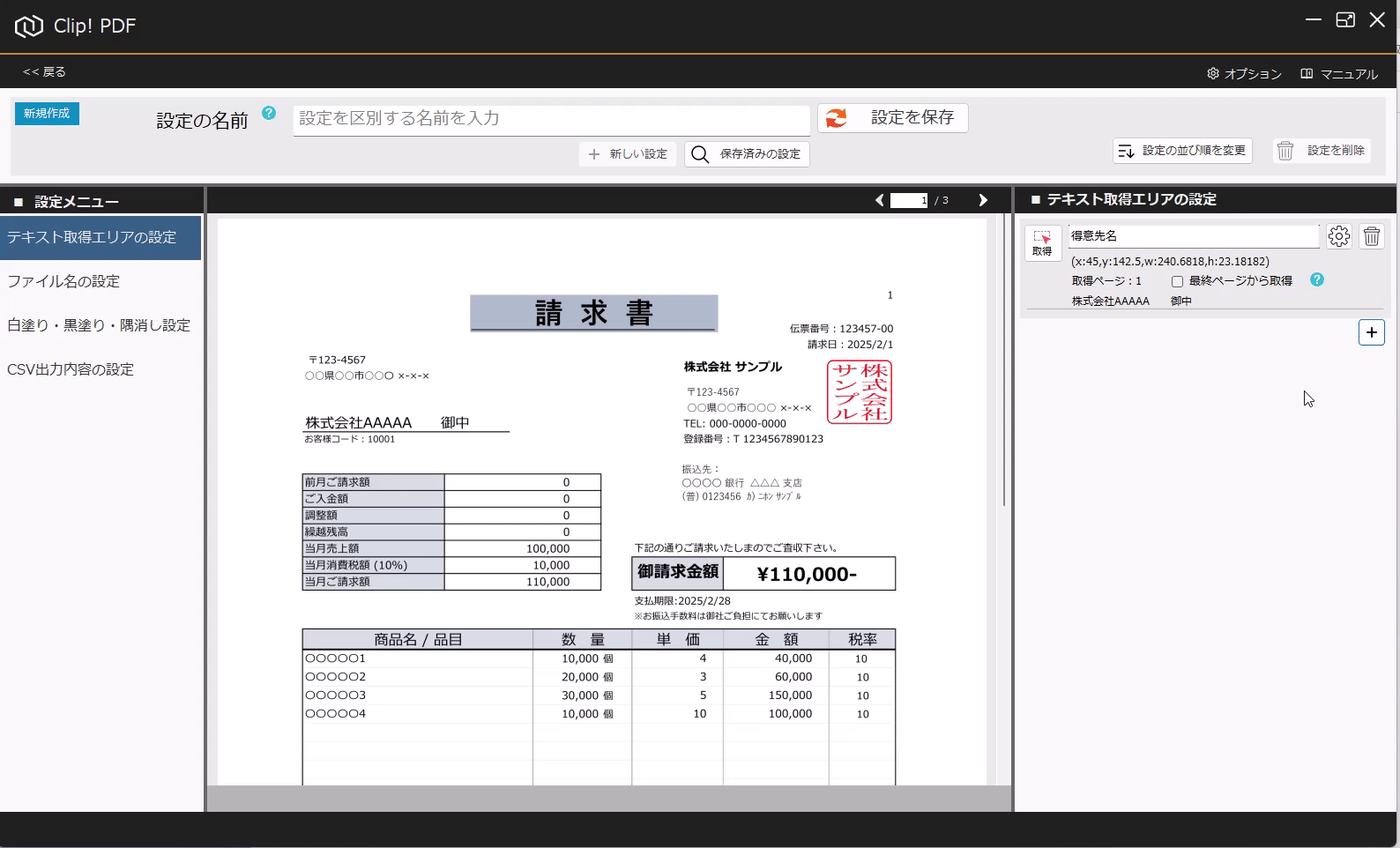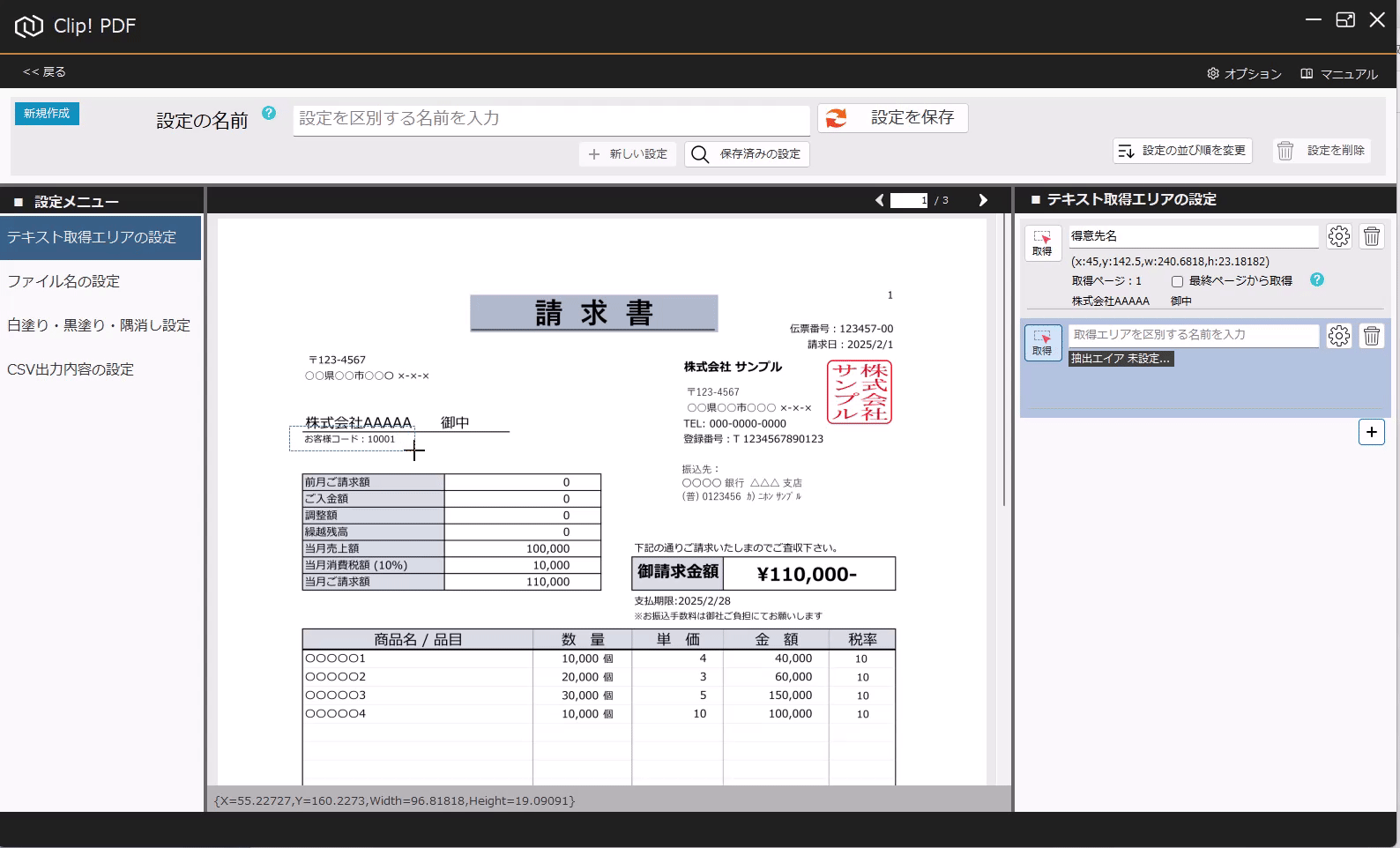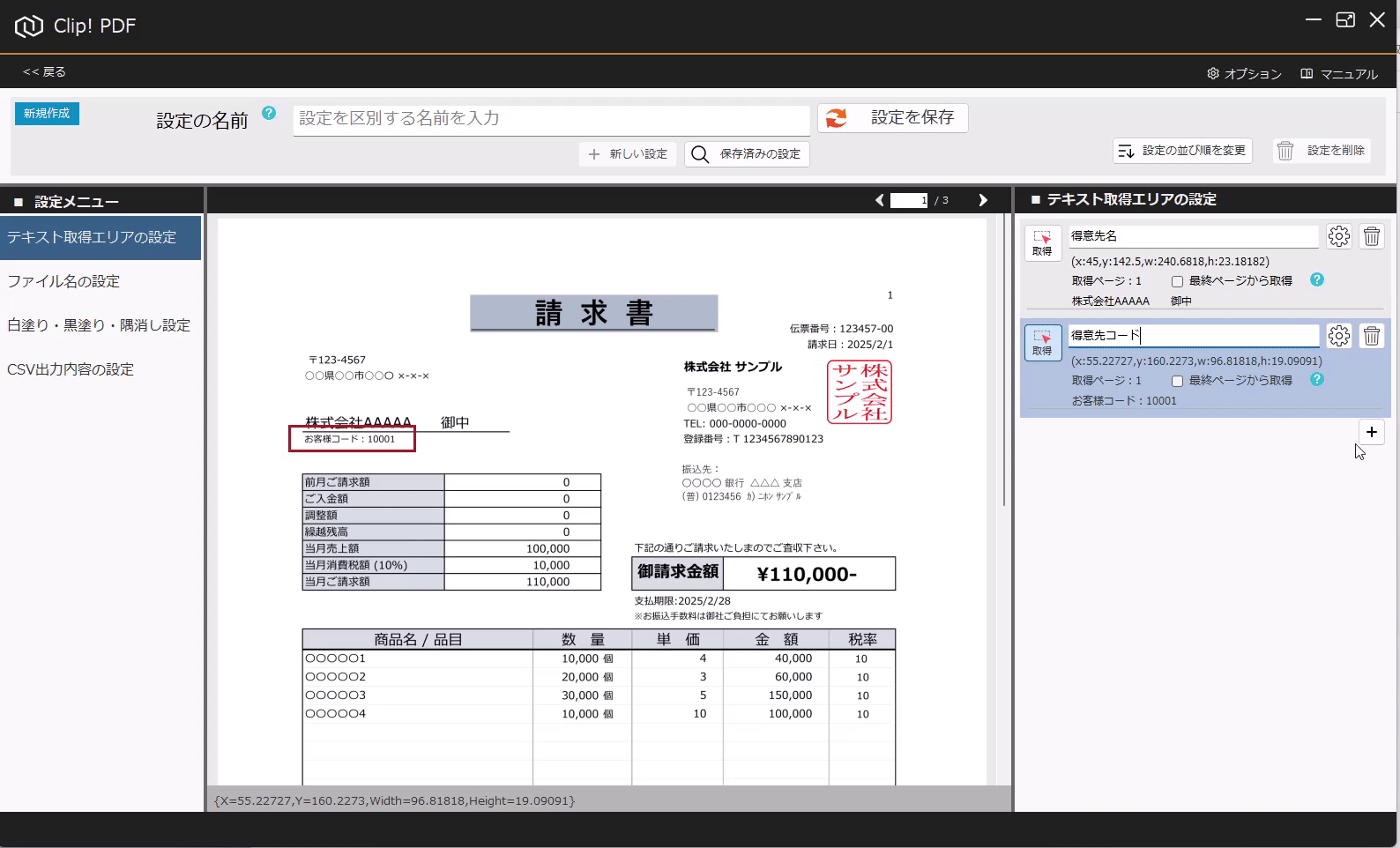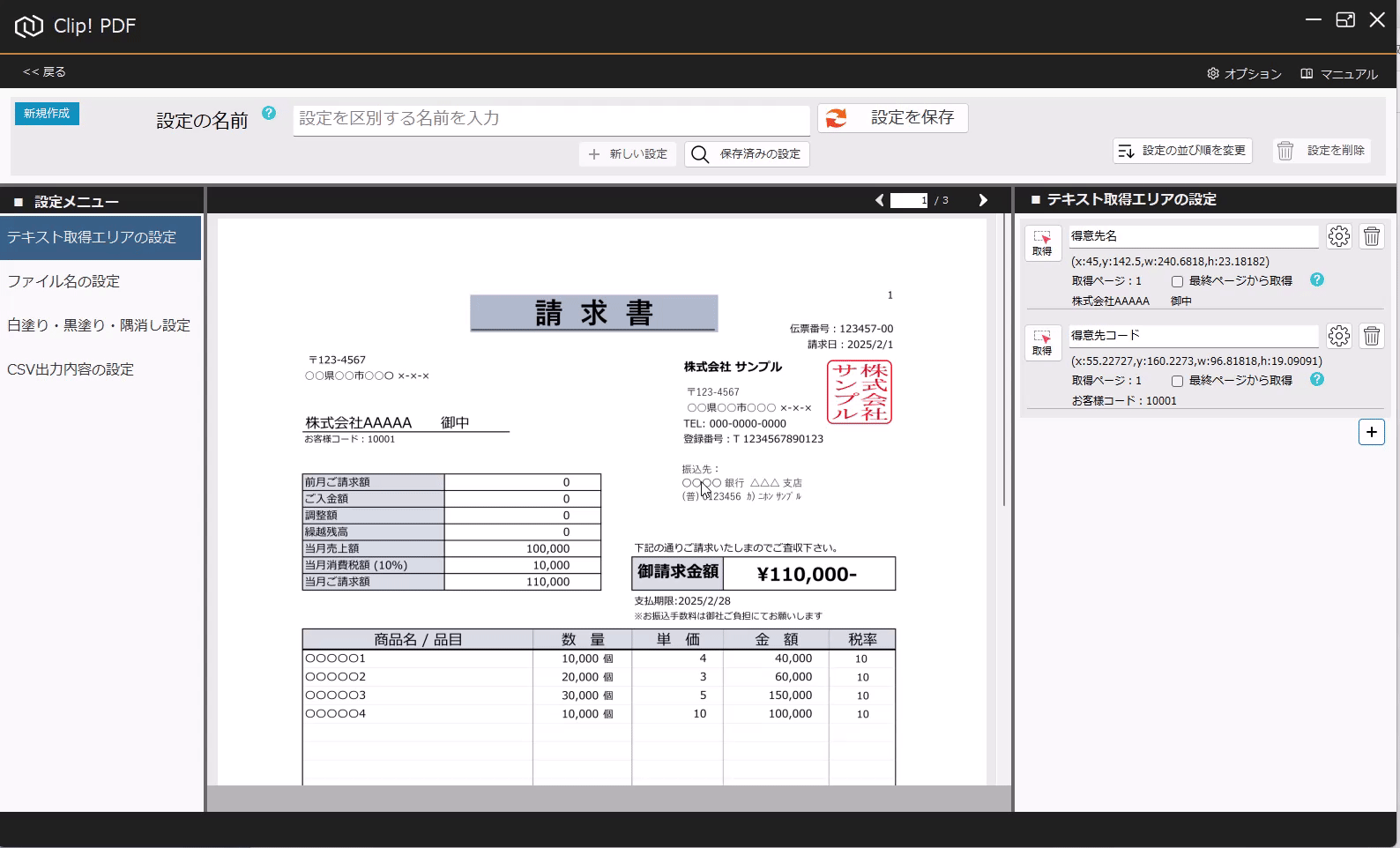
PDFからテキストを抽出する方法(基本) 投稿者:clippdf 投稿公開日:2025年3月8日 投稿カテゴリー:ガイド このガイドでは、PDF上のテキストを取得する設定方法を説明します。 「PDF上のテキストを一括取得」オプション機能について 「PDF上のテキストを一括取得」オプション機能は、単体ではテキストを抽出するだけで機能しません。しかし、他のオプション機能と組み合わせることで、より実用的に活用できます。 組み合わせ可能なオプション機能 「PDFのファイル名を一括変更」オプション機能 と組み合わせれば、取得したテキストをもとにファイル名を一括変更できます。 「PDFの不要な部分を一括消去」オプション機能 と組み合わせれば、特定の単語を含むページだけを不要な部分を一括消去できます。 「PDF上のテキストを自動でCSV出力」オプション機能 と組み合わせれば、大量のPDFから特定の位置のテキストを抽出し、CSVを作成することができます。 ご注意 PDFが画像として作成されている場合や、取得しようとしたテキストが画像として埋め込まれている場合など、テキスト情報を含まないためテキストを取得できません。PDFがテキストデータを持つ形式か確認してください。スキャンされたPDFなどはテキストを取得できません。特殊なフォントなども、正しく取得できない場合があります。 使用するオプション機能 PDF上のテキストを自動で一括取得 設定画面へ移動 設定画面を開きます。 PDFを選択 画面上部の「設定の名前」に、識別しやすい名称を入力します。 次に、画面中央の枠内に対象のPDFをドラッグ&ドロップしてください。 ※設定に使用したPDFはローカルPCに保存されます。機密情報を含むPDFの使用はお控えください。 テキストりエリアを設定 画面左の「設定メニュー」から、「テキスト取得エリアの設定」メニューを選択します。 画面右の「テキスト取得エリアの設定」メニューから「取得」ボタンをクリックします。 取得ボタンをクリックすると、テキスト取得エリア設定モードに変わり、背景が青色になります。 画面中央の請求書で、テキストを取得したいエリアをドラッグで囲みます。 テキストを正確に取得するために、最大文字数を考慮して、できるだけ広めに取得エリアを指定することがポイントです! テキストの取得を確認 ドラッグしたエリアのテキストが問題なく取得できるか確認しましょう。 PDFが画像として作成されている場合や、取得しようとしたテキストが画像として埋め込まれている場合、テキスト情報を含んでいないため、取得できません。PDFがテキストデータを持つ形式であることを確認してください。スキャンされたPDFなどはテキストが取得できません。また、フォントが特殊な場合や文字化けしている場合も、正しく取得できない可能性があります。 必ず正しくテキストが取得できていることを確認してください。 識別しやすいように、「得意先名」などの分かりやすい名前を入力します。 設定を追加する場合は「+(プラス)」ボタンをクリックします。追加した設定を削除する場合は、「ごみ箱」ボタンをクリックします。 設定を保存 テキスト取得エリアの設定が完了したら、画面上部の「設定を保存」ボタンをクリックして保存します。 タグ: PDF上のテキストを一括取得 その他の記事を読む 次の投稿PDFの最終ページからテキストを抽出する おすすめ PDFに画像挿入の活用事例 2025年4月7日 設定の表示順を変更するには 2025年3月5日 PDFの不要部分を消去する方法(基本) 2025年3月7日